STT Benchmark: Cohere Transcribe vs Gemma 4 #
TLDR #
Gemma 4 accepts raw audio as multimodal input now, so the obvious question: can it match a dedicated ASR model for transcription? Ran 50 LibriSpeech test-clean samples on an RTX 3090. Not even close. Cohere Transcribe wins on accuracy, speed, and VRAM.
The other finding that matters just as much: WER is actively misleading when evaluating post-processing. A perfect transcription run through a cleanup prompt -- the kind that adds commas, capitals, "Mr." instead of "mister" -- scores 13-16% WER against LibriSpeech's unpunctuated ground truth. The metric penalizes exactly the changes you'd want in a real transcript.
ASR Results #
Two caveats before the numbers:
- All three models output punctuated, capitalized text, but LibriSpeech ground truth is unpunctuated lowercase. That means every comma, period, and capital letter counts as a WER error. The raw WER numbers below are inflated by roughly 10 percentage points across the board -- I break this out in detail further down, but keep it in mind when reading the table.
- The Gemma models were run unquantized via Transformers, so they're much larger than a standard 4-bit quant, but I didn't see a straightforward way to use a 4-bit GGUF that enabled audio input.
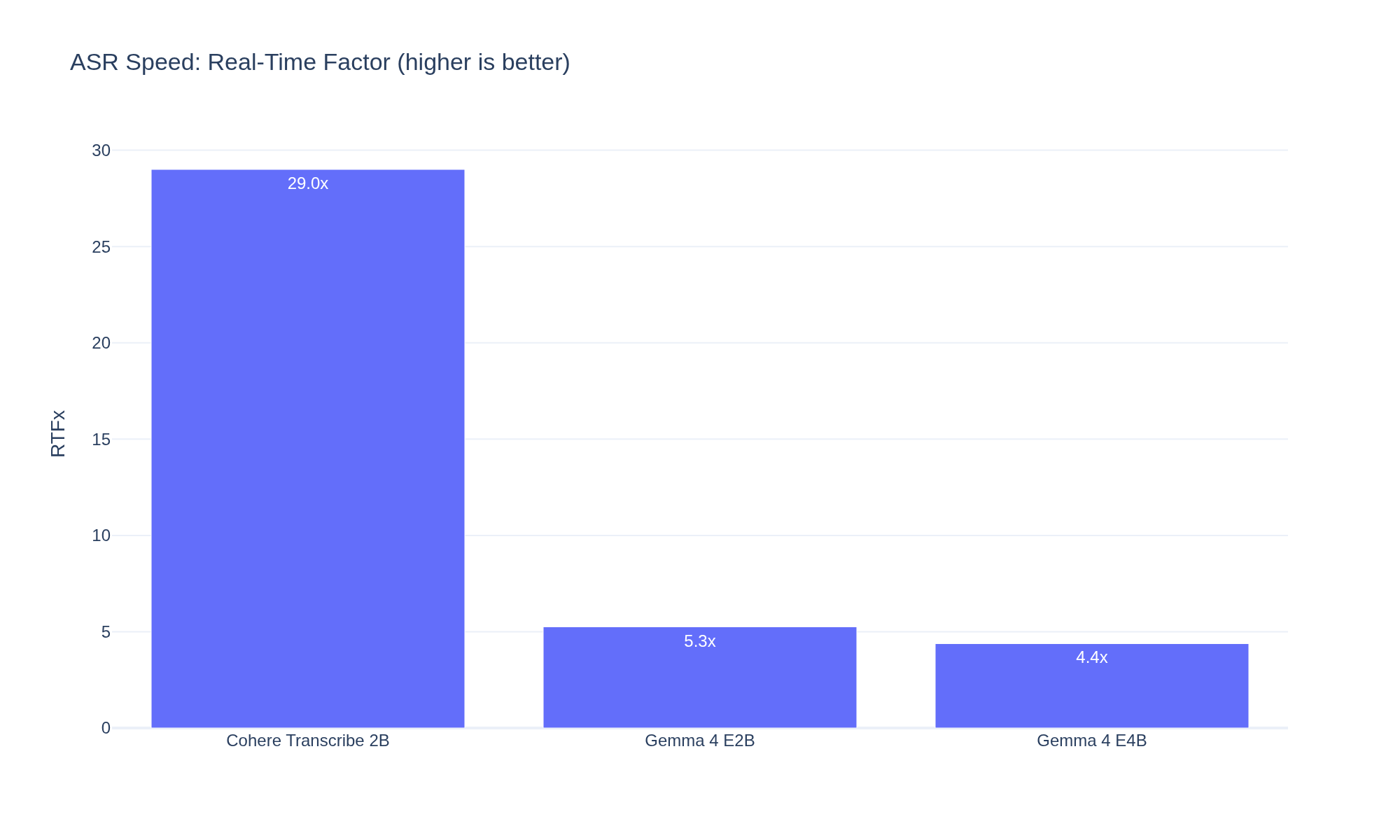
WER (Word Error Rate) -- percentage of words the transcript gets wrong via insertions, deletions, and substitutions. Lower is better. RTFx (Real-Time Factor) -- how many times faster than real-time the model transcribes. An RTFx of 29x means a 10-second clip is transcribed in ~0.34 seconds. Higher is better.
| Model | Type | WER | RTFx | VRAM |
|---|---|---|---|---|
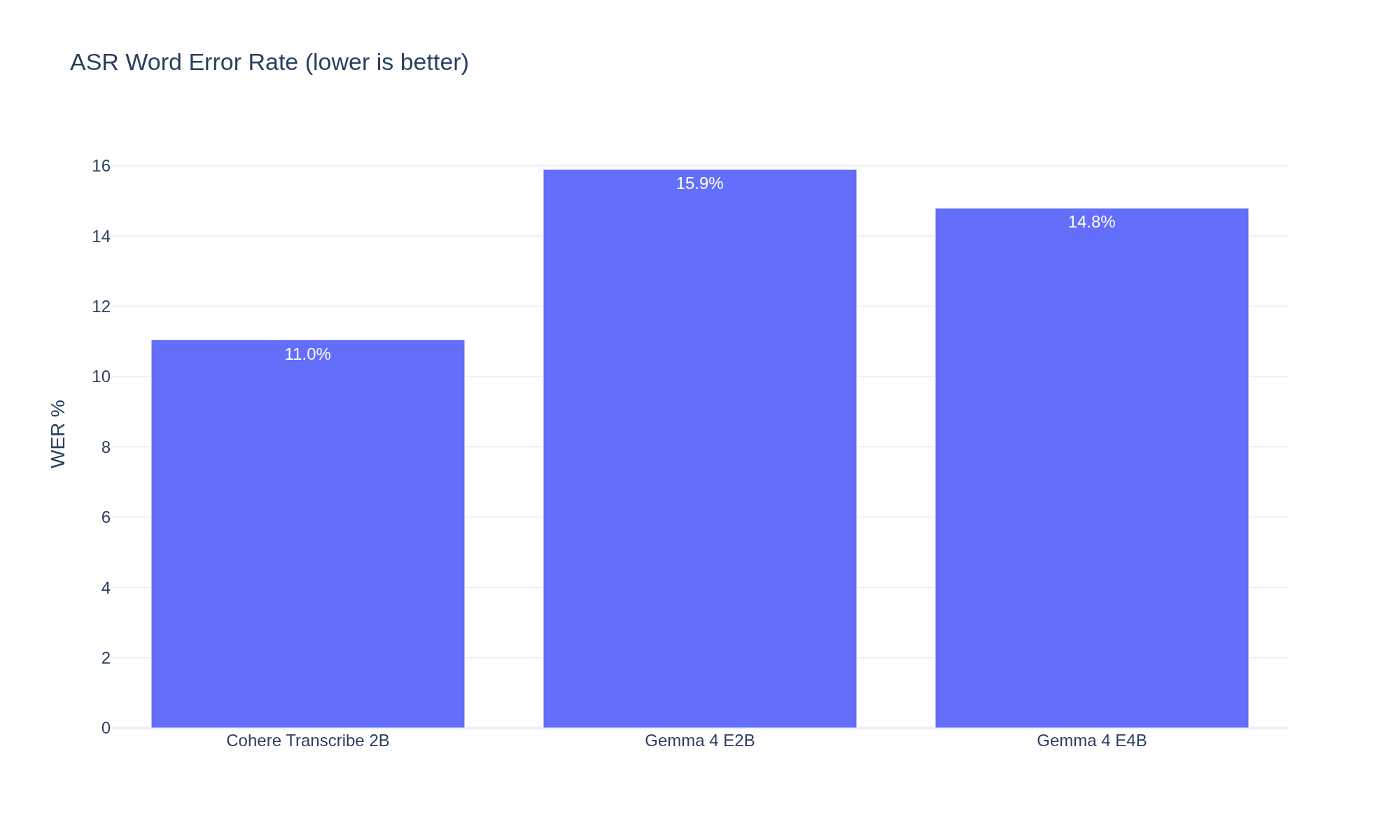
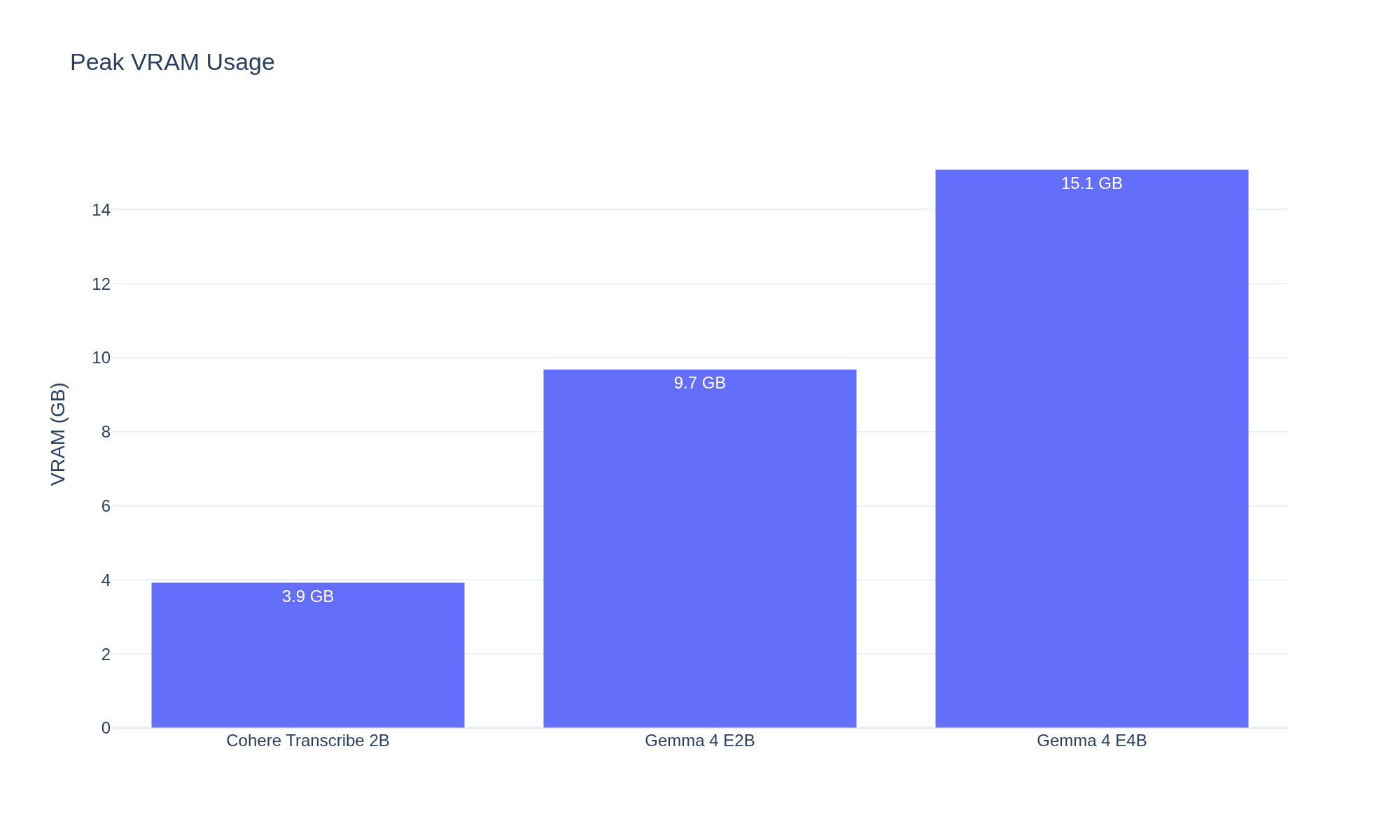
| Cohere Transcribe 2B | Dedicated ASR (Conformer) | 11.0% | 29.0x | 4.0 GB |
| Gemma 4 E4B | Multimodal LLM (BF16) | 14.8% | 4.4x | 15.1 GB |
| Gemma 4 E2B | Multimodal LLM (BF16) | 15.9% | 5.3x | 9.7 GB |
The Gap Is Structural #
Cohere is 6-7x faster than Gemma 4 while also being more accurate, using a quarter of the VRAM of even the smallest Gemma variant. The Conformer encoder-decoder architecture is built for this -- autoregressive text generation from audio tokens is not.
Gemma 4 E4B edges out E2B (14.8% vs 15.9% WER), but 1.1% for 3.4x the VRAM and slower inference is not a trade worth making.
The Punctuation Problem #
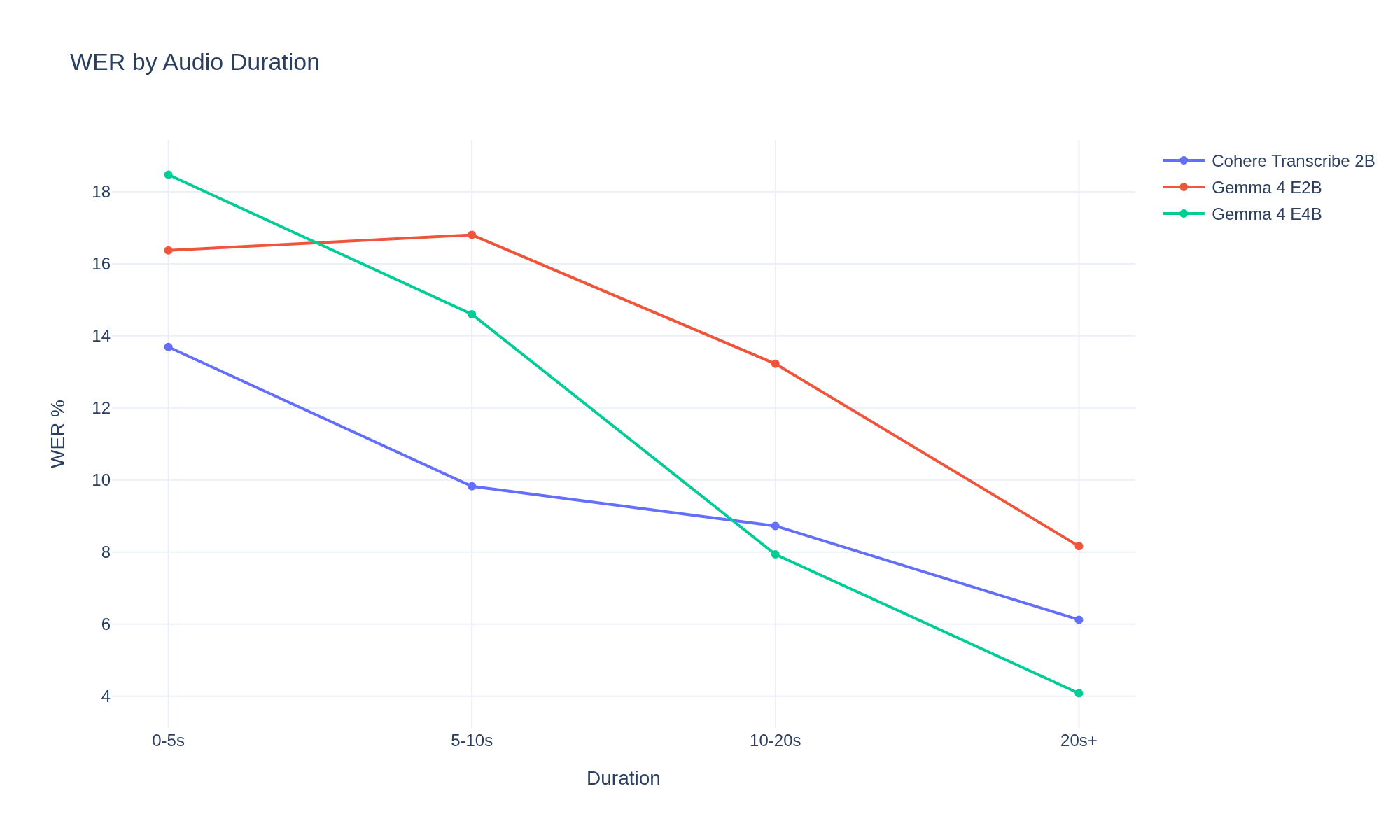
Here's a wrinkle: all three models output punctuation, but LibriSpeech ground truth is unpunctuated lowercase. Every comma and period counts as a WER error. Strip punctuation before scoring and the picture changes:
| Model | Raw WER | Punct-Stripped WER | Punctuation Penalty |
|---|---|---|---|
| Cohere Transcribe 2B | 11.0% | 1.0% | 10.0% |
| Gemma 4 E4B | 14.8% | 4.6% | 10.2% |
| Gemma 4 E2B | 15.9% | 4.4% | 11.5% |
Cohere still wins -- 44/50 perfect transcriptions after stripping punctuation, vs 28/50 for both Gemma variants. The penalty is roughly equal across models (~10%), so the ranking doesn't change. But the real word-level accuracy gap is ~3.5%, not the ~4-5% that raw WER suggests.
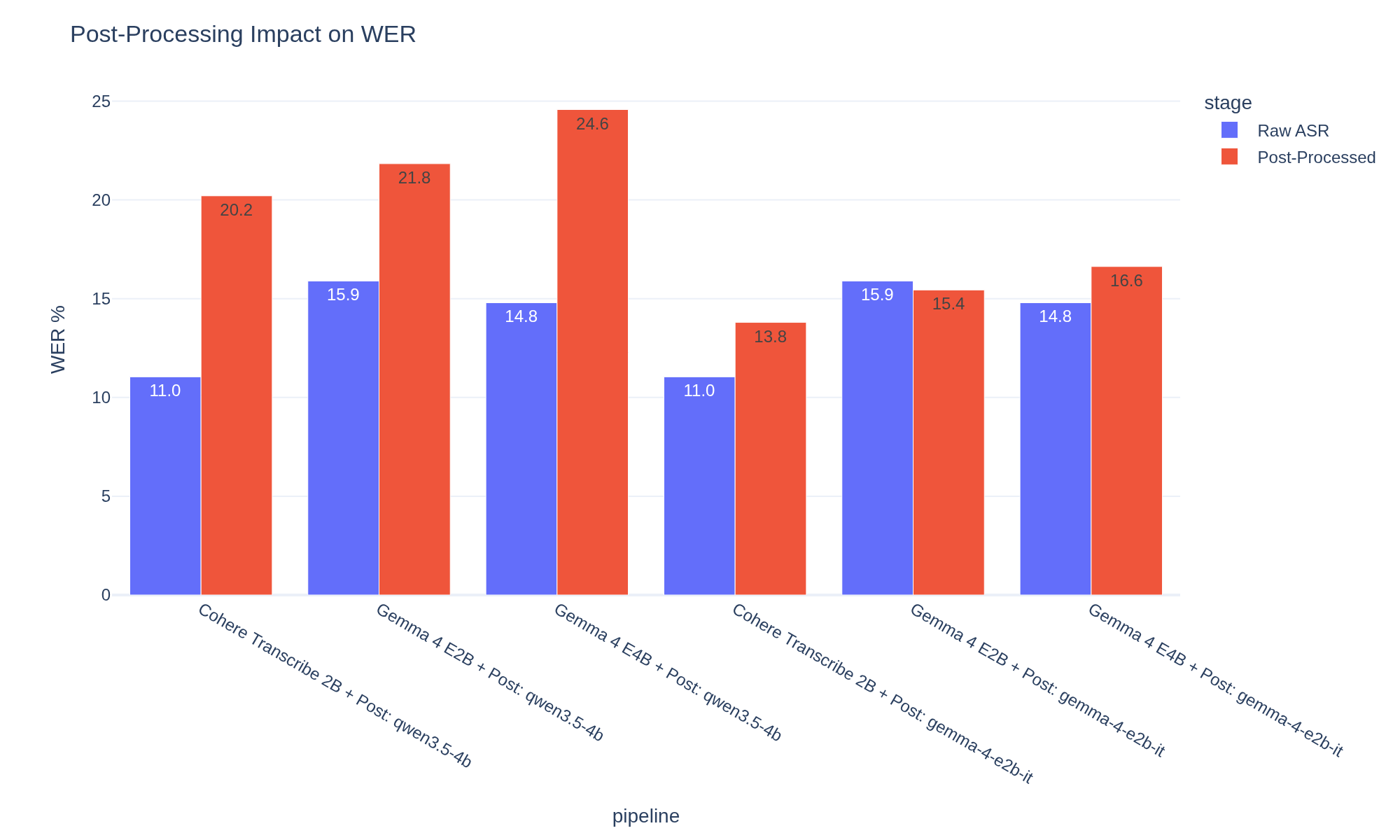
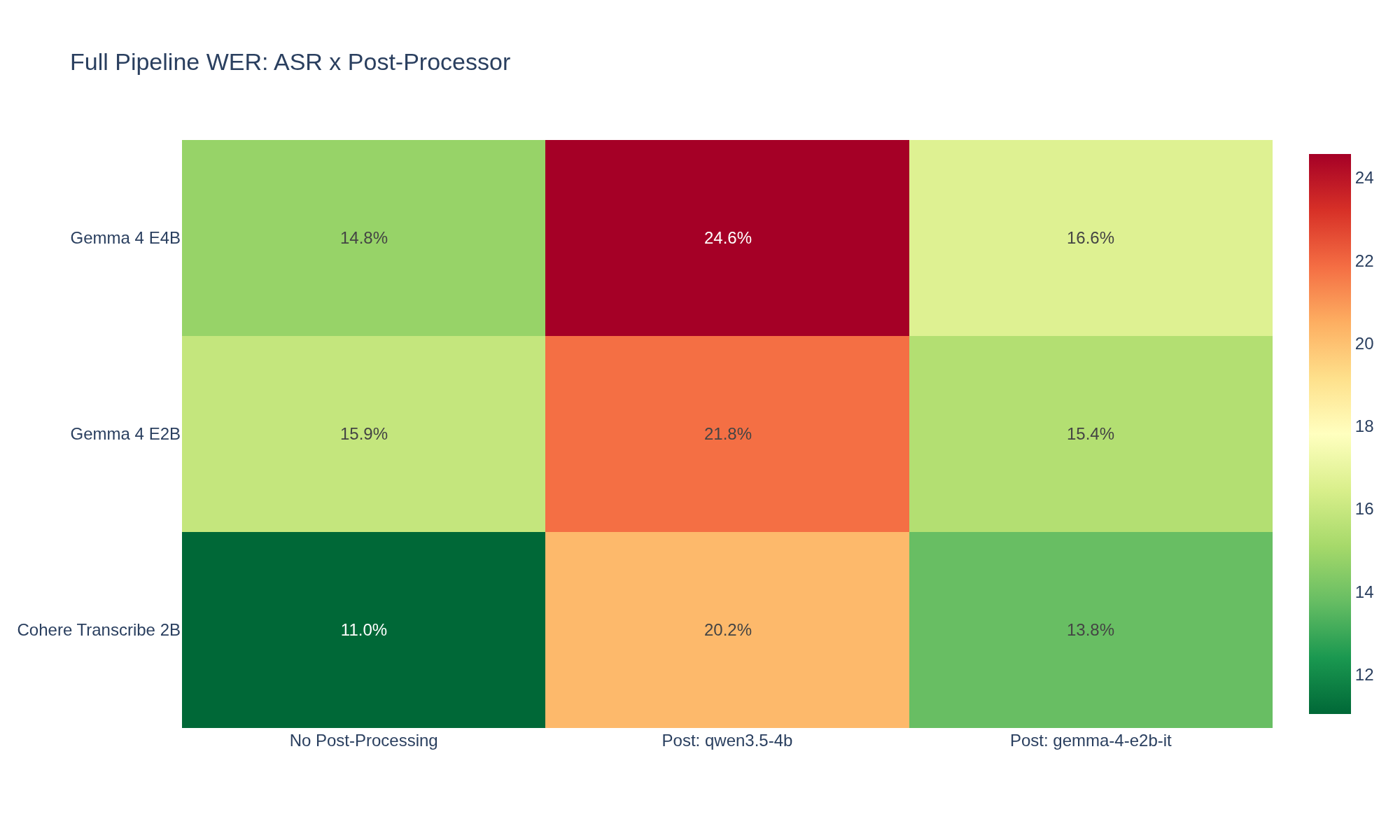
Post-Processing Results #
The other question worth answering: does LLM post-processing help or hurt? Ran the raw transcriptions through the same custom cleanup prompt I use for Handy (filler removal, punctuation, spoken corrections) with two models via LM Studio: Qwen 3.5 4B and Gemma 4 E2B.
| Pipeline | Raw WER | Post-Processed WER | Delta |
|---|---|---|---|
| Cohere + Qwen 3.5 4B | 11.0% | 20.2% | +9.2% |
| Cohere + Gemma 4 E2B | 11.0% | 13.8% | +2.8% |
| Gemma 4 E2B + Qwen 3.5 4B | 15.9% | 21.8% | +5.9% |
| Gemma 4 E2B + Gemma 4 E2B | 15.9% | 15.4% | -0.5% |
| Gemma 4 E4B + Qwen 3.5 4B | 14.8% | 24.6% | +9.8% |
| Gemma 4 E4B + Gemma 4 E2B | 14.8% | 16.6% | +1.8% |
The Metric Is Fighting the Task #
At first glance, post-processing makes everything worse. That's misleading. LibriSpeech ground truth is unpunctuated lowercase. The cleanup prompt adds commas, capitalization, "Mr." instead of "mister" -- exactly what you'd want in a real transcript. WER penalizes all of it.
Point is though, Gemma 4 E2B is a noticeably better post-processor than Qwen 3.5 4B. More conservative, fewer destructive word-level changes -- 2.8% vs 9.2% WER increase on Cohere output.
Strip punctuation from both sides and the picture gets clearer. Gemma E2B post-processing adds only +0.3-0.9% real WER -- basically harmless. Qwen 3.5 still adds +3.6-5.9%, which means it's genuinely mangling words, not just adding formatting.
Post-Processing Examples #
A few samples to make the point concrete. WER goes up, but read the actual text -- you'd take the post-processed version almost every time.
Example 1: Perfect match destroyed by punctuation #
| Text | |
|---|---|
| Ground truth | when this had been accomplished the boolooroo leaned over to try to discover why the frame rolled away seemingly of its own accord |
| Raw ASR (WER 0.0%) | when this had been accomplished the boolooroo leaned over to try to discover why the frame rolled away seemingly of its own accord |
| + Qwen 3.5 (WER 15.8%) | When this had been accomplished, Boolooroo leaned over to try to discover why the frame rolled away, seemingly of its own accord. |
| + Gemma E2B (WER 13.2%) | When this had been accomplished, the boolooroo leaned over to try to discover why the frame rolled away, seemingly of its own accord. |
Perfect match becomes 13-16% WER because every comma and capital letter is an "error." The metric is punishing what is actually true human preference. The benchmark is useful, but it's not directly applicable to this use case. Still value in it, but it's a good example of why you need to dig deeper into the data and not blindly accept the topline numbers.
Example 2: Proper nouns and abbreviations #
| Text | |
|---|---|
| Ground truth | i wish you good night she laid her bony hands on the back of mister meadowcroft's invalid chair |
| Raw ASR (WER 9.1%) | i wish you good night. she laid her bony hands on the back of mister meadowcroft's invalid chair |
| + Qwen 3.5 (WER 11.4%) | I wish you good night. She laid her bony hands on the back of Mr. Meadowcroft's invalid chair |
| + Gemma E2B (WER 11.4%) | I wish you good night. She laid her bony hands on the back of Mr. Meadowcroft's invalid chair |
Both models abbreviate "mister" to "Mr." and capitalize the proper noun.
Example 3: Qwen over-edits, Gemma holds back #
| Text | |
|---|---|
| Ground truth | to night there was no need of extra heat and there were great ceremonies... |
| Raw ASR (WER 0.0%) | to night there was no need of extra heat and there were great ceremonies... |
| + Qwen 3.5 (WER 16.7%) | To night, there was no need for extra heat, and there were great ceremonies... |
| + Gemma E2B (WER 8.3%) | Tonight there was no need of extra heat and there were great ceremonies... |
Qwen adds commas and changes "of" to "for" -- unnecessary edits that add to WER, and rightly so. Gemma correctly merges "to night" into "Tonight" and leaves the rest alone. This pattern repeats across the dataset -- Gemma 4 E2B is the better post-processor by a wide margin.
Takeaways #
Dedicated ASR wins and it's not close. Cohere Transcribe beats Gemma 4 on accuracy, speed, and VRAM. Multimodal LLMs accepting audio is genuinely useful for understanding and reasoning about speech, but if all you need is a transcript, purpose-built architectures are better tools for the job.
E4B vs E2B doesn't matter much. 1.1% WER gap, 3.4x the VRAM. Not worth it.
Post-processing is preferable for dictation in a computer-use scenario, despite the WER implying it's not. The cleanup prompt produces text you'd actually want to work with -- proper punctuation, capitalization, abbreviations. WER can't see that.
WER is the wrong metric for post-processing. As described above, it penalizes exactly the cleanup that makes transcripts readable. Punctuation-aware metrics or human eval would be more honest here.
Setup #
- Repo: stt-benchmark
- GPU: NVIDIA RTX 3090 (24 GB VRAM)
- OS: Ubuntu Linux 24.04
- Dataset: LibriSpeech test-clean, 50 samples (seed=42)
* Code and post produced in cooperation with a heavily modified version of Claude Code. Not vibe-coded, it's all been read, reviewed and edited, but while distracted by youtube videos on the Artemis II launch at 1AM, so grain of salt y'all, but still, a question that bugged me is answered.